
Node Exporter+Prometheus+Grafana多机器服务监控系统搭建(1)
前言
当我们拥有的服务器和建立的服务越来越多,手动管理便会逐渐显得力不从心,与此同时确保自己能够顾及到所有服务的正常运行也颇具难度。
想象下面的场景:一台不起眼的服务器上的一个不起眼的服务炸了,由于有比它重要得多的服务,因此几乎不太可能在它上面投入过多注意力,于是它便有可能维持炸的状态几周甚至几个月,这不是我们希望看到的。
在一台机器上,我们可以很简单方便地使用 systemctl status 和 docker ps -a 这两个指令检查服务情况。那么对于多台机器呢?在运维实践中,为了最高的维护效率和便利性,我们希望监控系统能做到下面两点:
- 在一个地点通过统一的仪表板同时掌控多个机器的运行状况,并且可以查看具体的运行细节,不必专门进入机器shell查询;
- 在服务挂掉的时候,能够自动通过Email/telegram/…等易于被人类看到的方式通知我们(毕竟不能期待运维人员24小时盯着仪表板)。
幸运的是,我们有一套完全开源且易于部署的方案,Node Exporter+Prometheus+Grafana.这也是运维监控的行业标准级实现。具体来说:
-
Node Explorer安装在各台需要监控的机器上,负责拉取机器和服务运行的各项指标数据; -
Prometheus和Grafana安装在一台监控主机上,Prometheus从各台被监控机的Node Explorer中拉取数据并进行汇总,作为外部数据源传递给Grafana进行高级可视化以及告警。
注意,Prometheus和Grafana实例的资源开销较高,因此监控主机的选择应该优先挑选自己资源比较充足的机器
Prometheus和Node Explorer分别是开源数据汇总和数据收集的较好实践,二者配合其实就足以满足建立一个基本监控系统的需求,这里使用Grafana是因为其社区有大量可直接复用的Dashboard,懒人福音。

第一步:在各台机器上部署Node Explorer
我们采用Docker compose部署,需要确保每台机器都安装了Docker和Docker compose。若未安装请点击链接查看安装方法。
在每台机器上,新建一个docker-compose.yml文件(位置随意),写入下面内容:
services:
node-exporter:#若你已经有使用docker compose运行的服务,则只把这个块加到你的service块下面
image: quay.io/prometheus/node-exporter:latest
container_name: node-exporter
restart: always
# 核心配置1:使用宿主机网络,这样不需要端口映射,直接占用宿主机的 9100 端口
# 同时也确保了网络流量监控的准确性
network_mode: host
# 核心配置2:使用宿主机 PID 空间,以便获取进程相关的准确指标
pid: host
# 核心配置3:挂载文件系统
volumes:
# 将宿主机的根目录 '/' 挂载到容器内的 '/host'
# :ro 表示只读 (Read Only),安全起见
# :rslave 表示递归从属挂载,这对于监控挂载在宿主机上的其他硬盘/分区非常重要
- '/:/host:ro,rslave'
# 下面这条必须加上,否则docker内无法读取宿主机dbus,会导致监控不到任何宿主机上的systemd服务
- '/var/run/dbus/system_bus_socket:/var/run/dbus/system_bus_socket:ro'
# 告诉 node-exporter 去 '/host' 目录读取数据,而不是容器自己的根目录
command:
- '--path.rootfs=/host'
- '--collector.systemd'
# 默认可能不采集任何服务,建议配置正则来匹配你想监控的服务
# 下面的正则表示:监控 docker, ssh, cron, nginx, mysql 等服务。
# 如果你想监控所有服务(不推荐,数据量太大),可以用 '.+'
- '--collector.systemd.unit-include=(docker|containerd|sshd?|cron|nginx|mysql|grafana|prometheus|frps|sing-box).service'
- 可选但强烈推荐:使用
cadvisor探针监测机器上docker容器运行情况
如果说Node Explorer是一个用于检测系统基本状况和systemd服务的“探针”,那么对于docker方式运行的服务,这个“探针”是cadvisor。
在上述docker-compose.yml的service块中加入下面内容,注意缩进要严格:
cadvisor:
# Google 官方镜像,注意:如果你在大陆,可能需要梯子或寻找 gcr.io 的镜像源
# 注意,需要用最新版的镜像,旧版镜像对于cGroups v2不支持,可能导致后续Grafana中不显示数据
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
restart: always
ports:
- "8080:8080" # cAdvisor 默认运行在 8080 端口
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
devices:
- /dev/kmsg
privileged: true
上述编辑均完成后,在docker-compose.yml文件所在的目录下运行docker compose up -d,之后:
curl 127.0.0.1 -p 9100
curl 127.0.0.1 -p 8080
可以看到输出,说明该机器上两个探针安装正常,对你拥有的所有机器重复上述步骤。
为了让上述探针服务能够被主机访问到,记得开放上述9100和8080端口的防火墙。
第二步:在监控主机上部署Prometheus+Grafana
祝贺!我们现在已经完成了数据采集系统的部署,与此同时,我们也对docker compose方式部署服务有了更深的的理解。接下来让我们开始对监控主机进行一番操作,以实现数据的汇总和展示。
Prometheus需要在宿主机上持久化数据,因此我们需要指定其数据目录并挂载:
mkdir -p my-monitor/prometheus
cd my-monitor
之后写Prometheus的配置文件:vim prometheus/prometheus.yml
global:
scrape_interval: 15s # 每15秒抓取一次数据
scrape_configs:
- job_name: 'node-exporter'
static_configs:
# 这里的 targets 列表填入所有你要监控的主机 IP:9100
- targets: ['127.0.0.1:9100'] # 主机 A (自己)
labels:
instance: 'A'
- targets: ['1.2.3.4:9100'] # 主机 B
labels:
instance: 'B'
- targets: ['5.6.7.8:9100'] # 主机 C
labels:
instance: 'C'
- job_name: 'cadvisor'# 必须exactly match,否则多数Grafana面板抓不到数据
static_configs:
# 这里的 targets 列表填入所有你要监控的主机 IP:9100
- targets: ['127.0.0.1:8080'] # 主机 A (自己)
labels:
instance: 'A'
- targets: ['1.2.3.4:8080'] # 主机 B
labels:
instance: 'B'
- targets: ['5.6.7.8:8080'] # 主机 C
labels:
instance: 'C'
接下来就可以编写docker-compose.yml定义监控实例了:
services:
# 1. Prometheus: 负责收集数据
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: always
volumes:
# 注意将下面的路径改为你的绝对路径
- /path/to/my-monitor/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
ports:
- "9090:9090"
# 2. Grafana: 负责展示数据
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: always
volumes:
# 注意将下面的路径改为你的绝对路径
- /path/to/my-monitor/grafana_data:/var/lib/grafana
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin # 初始密码,登录后建议修改
depends_on:
- prometheus
volumes:
prometheus_data:
grafana_data:
注意不要和已有的compose配置冲突。接下来,docker compose up -d,之后开放3000端口的防火墙,就可以在浏览器上输入https://<监控主机ip>:3000访问Grafana监控面板了!使用刚刚设置的密码登录,然后最好在设置中修改密码。
第三步:导入监控面板
初始的Grafana没有任何数据展示。为了看到系统的运行状态,我们需要创建Dashboard。幸运的是,Grafana社区中有很多预制的Dashboard我们可以直接拿来用。
首先,我们可以导入一个最简单的系统基本信息集成面板:
-
添加数据源(也就是我们部署的Prometheus)
-
点击左侧菜单的 Connections -> Data Sources。
-
点击 Add new data source。
-
选择 Prometheus。
-
在 Prometheus server URL 一栏输入:http://prometheus:9090
-
注意:这里我们用的是 docker 容器名,而不是 localhost,因为 Grafana 容器需要通过 Docker 网络访问 Prometheus 容器。
-
拉到最下方,点击 Save & test。如果显示绿色勾勾 “Successfully queried…“,说明连接成功。
-
-
导入Dashboard
-
点击左侧菜单的 Dashboards。
-
点击右上角的 New -> Import。
-
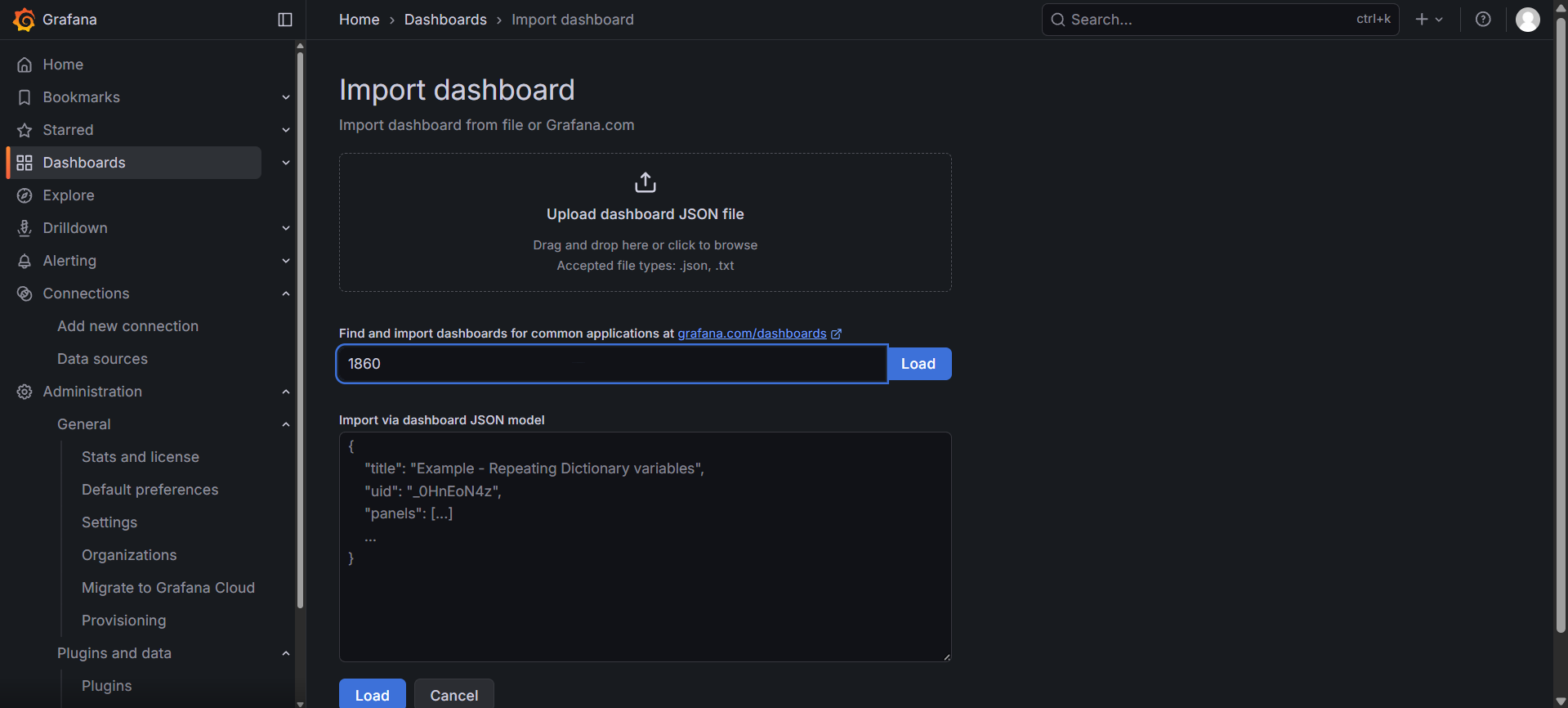
在 Import via grafana.com 下方的输入框中,输入 ID:1860。这是官方推荐的 “Node Exporter Full” 中文/英文通用面板。
-
点击 Load。
-
在下方的 Prometheus 选项中,选择你刚才添加的数据源。
-
点击 Import。
-
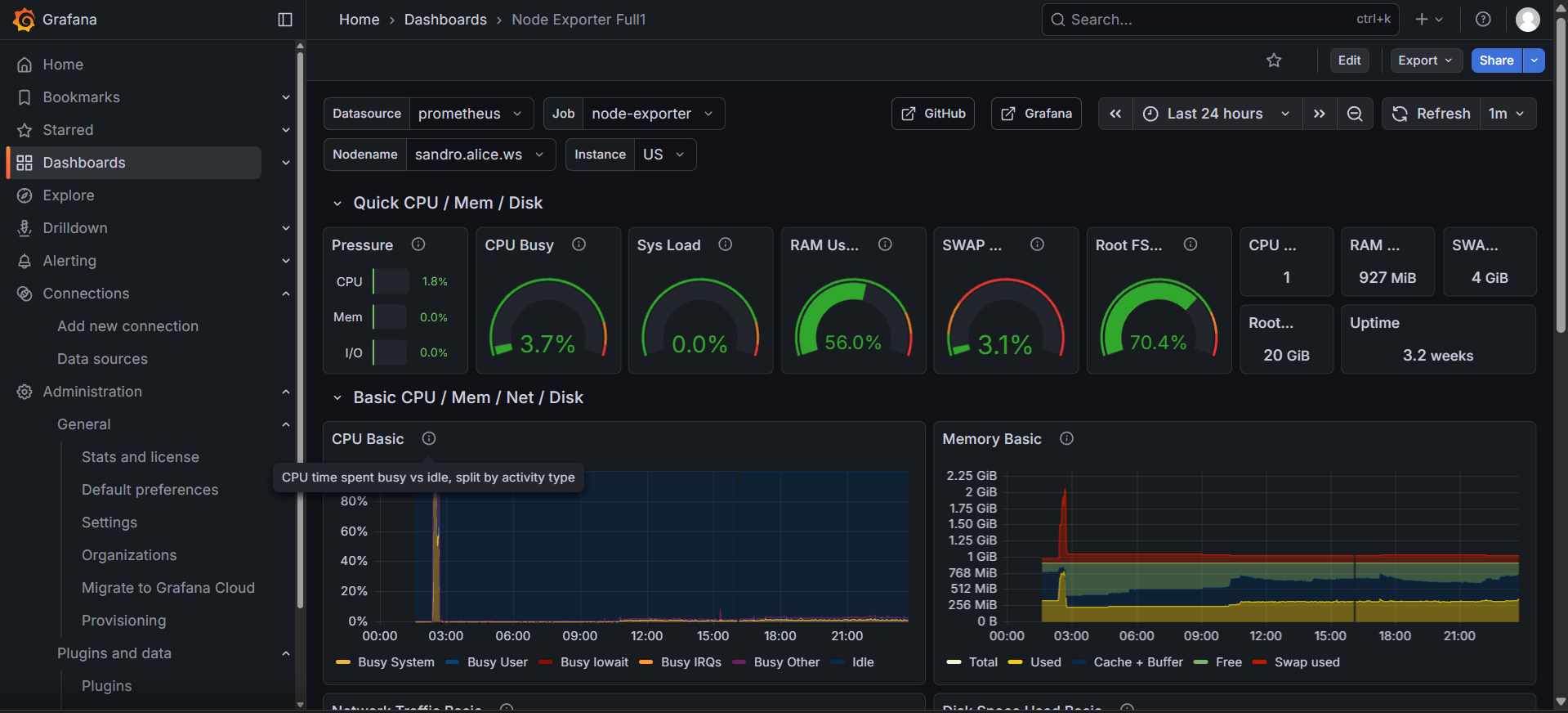
完成后,就可以看到图示的监控界面啦!
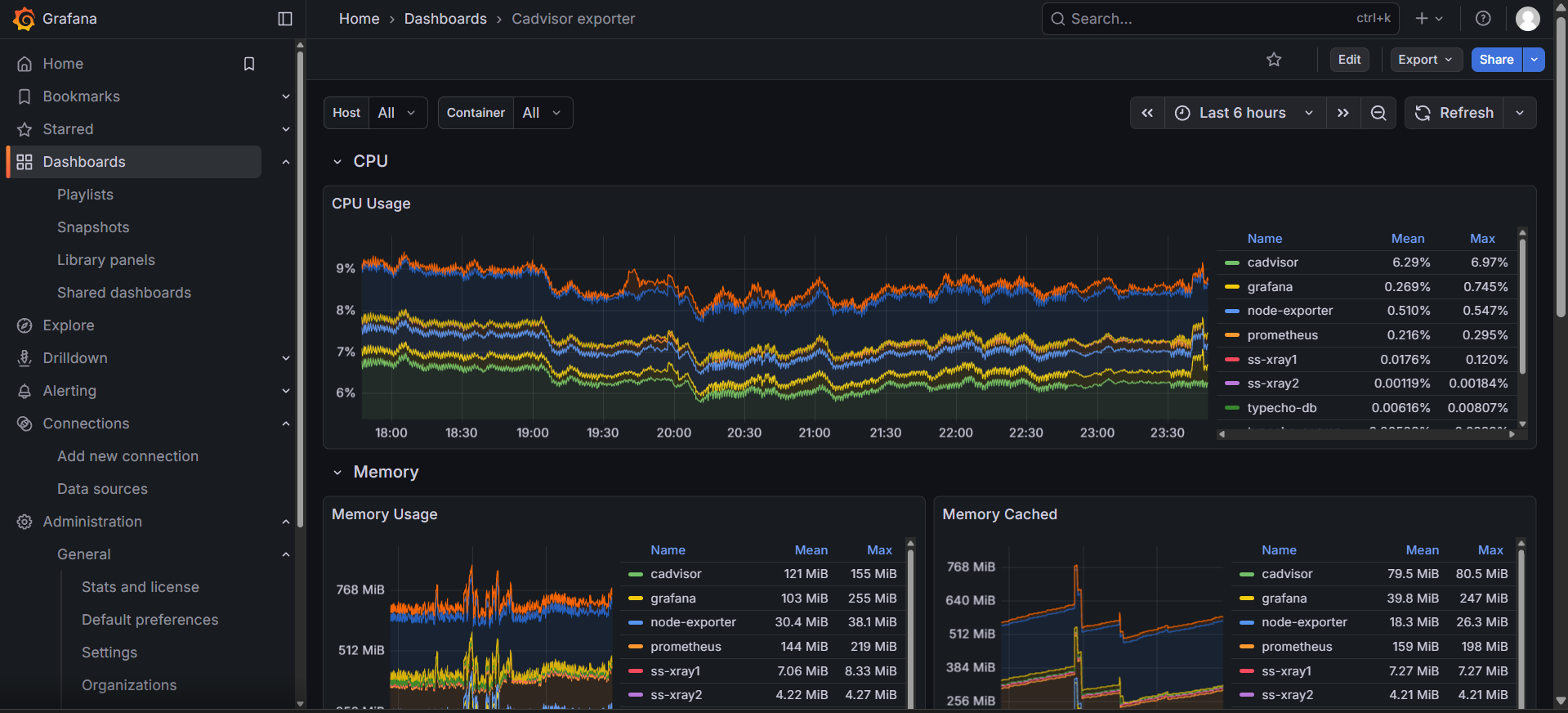
1860没有docker服务的监控。我们也可以导入一个专门的Dashboard做这个事情:14282。重复上述导入过程,就可以在Dashboard中看到docker服务的运行状态了。
大功告成!我们现在已经完成了第一个目标了,但是接下来的告警设置还有硬仗要打,我们将在下一篇文章中详细介绍。