
Node Exporter+Prometheus+Grafana多机器服务监控系统搭建(2)
我们已经在上一篇文章中讲述了Grafana监控系统的搭建,但是要想不用定期看仪表板,我们还需要设置Grafana,让它自动告警。这篇文章中采用邮件告警方式,其他告警信道配置逻辑基本一致,可以根据自己需要尝试。
第一步:邮件配置
Grafana页面中无法配置发信设置,需要在docker服务启动时传入环境变量。
在Grafana的docker-compose.yml块中的environments:块下面加入下面配置:
- GF_SMTP_ENABLED=true
# SMTP 服务器地址 (Gmail: smtp.gmail.com:587, QQ: smtp.qq.com:465)
- GF_SMTP_HOST=smtp.qq.com:465
# 发件人名称
- GF_SMTP_FROM_NAME=Grafana Alert
# 发件人邮箱地址
- GF_SMTP_FROM_ADDRESS=你的邮箱@qq.com
# 用户名 (需要是你登陆webmail时用的登录名)
- GF_SMTP_USER=你的邮箱@qq.com
# 密码 (注意:这里通常是 SMTP 授权码/应用密码,不是你的QQ/Google登录密码!)
- GF_SMTP_PASSWORD=你的授权码
# 跳过证书验证 (可选,部分自建邮件服务器需要)
- GF_SMTP_SKIP_VERIFY=true
注意:建议不要使用Outlook邮箱,原因是实测中Outlook在TLS握手时会传送一个巨型帧,在多数MTU=1500的机器上容易把这个巨帧丢弃导致timeout错误, 或者Microsoft 对于某些非标准 TLS 客户端的兼容性问题,或者 Go 语言库与 Outlook 的 TLS 握手不兼容,基本无法通过测试。
之后重启Grafana,然后测试邮件是否配置好:
-
进入 Grafana -> Alerting (左侧铃铛图标) -> Contact points。
-
应该能看到默认的 grafana-default-email,点击右侧的 Edit (或者新建一个)。
-
在 Addresses 里填入你的接收邮箱。
-
点击顶部的 Test 按钮 -> Send test notification。
-
确认你的邮箱收到了测试邮件。如果没有,请检查 docker logs grafana 看报错信息。
第二步:创建告警规则
核心:PromQL查询。
想要实现自动告警,便是要在机器满足特定条件下触发Grafana发送邮件,而特定条件是否满足可以通过对Prometheus的数据进行PromQL查询很容易地得到。
首先,编写一个简单的docker服务告警规则:
-
进入 Grafana -> Alerting -> Alert rules -> + New alert rule。
-
Step 1: Define query
选择数据源:Prometheus。
输入 PromQL(逻辑:统计该容器名字出现的次数,如果活着就是1,挂了就是0):
count by (instance, name) (container_last_seen{name="my-service"}) # OR vector(0) 是为了防止容器彻底挂掉后 Prometheus 查不到数据导致返回“空”,从而无法触发“小于1”的判断。加上这个,如果查不到数据,它会返回 0。运行查询,确保图表有线。
-
Step 2: Define alert conditions
Reduce: Function 选 Last (取最新值)。
Threshold: Input A is below 1。如果数值小于 1(即等于 0),则触发告警。
-
Step 3: Set evaluation behavior
Folder: 随便选一个或新建一个(如 “Docker Alerts”)。
Evaluation group: 新建一个(如 “1m check”),Interval 设为 1m(每分钟查一次)。
Pending period: 1m(持续挂掉1分钟才发邮件,防止网络抖动误报)。
Configure no data and error handling:
Alert state if no data or all values are null: Alerting (这一步很关键!如果容器彻底消失,可能连 0 都没返回,这时要强制视为告警)。
-
Step 4: Add annotations
Summary: [紧急] 服务异常: ()
Description: 检测到服务器 上的服务 当前状态异常。请立即检查该机器的运行状况。
Save rule and exit。
接下来是systemd服务的告警规则,其余部分可以仿照上面步骤进行,区别是需要把PromQL逻辑改为node_systemd_unit_state{name="docker.service", state="active"}。
- 讨论:当我们写完告警策略,进行测试时,会发现发送的邮件得到的服务名称和机器名称标签显示不出来。
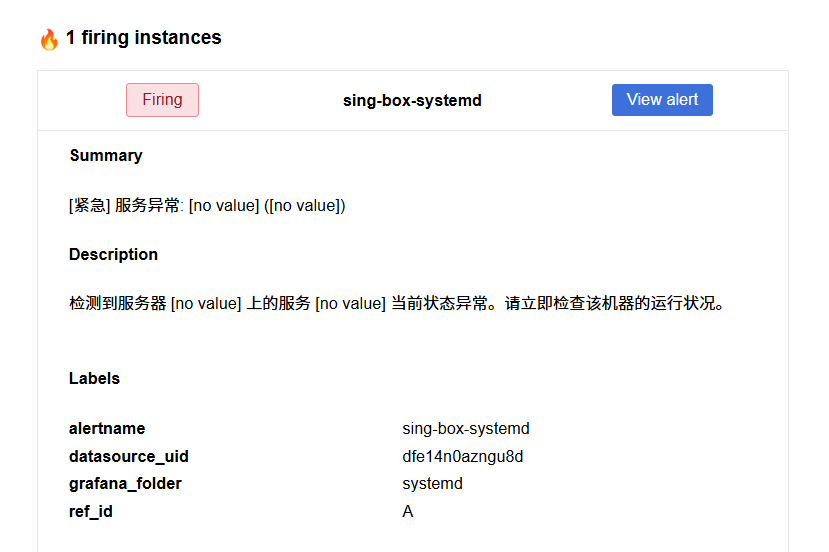
这是因为当服务停止运行时,node_systemd_unit_state{name="docker.service", state="active"}的条目会直接消失,并且触发No Data Alert。
而在“无数据”的状态下,Prometheus 无法提供任何标签(Labels),因为它根本就没有读到那条记录,自然不知道是哪个 instance 或哪个 name 消失了。
解决:补0
尝试将PromQL改为下面逻辑:
node_systemd_unit_state{name="sing-box.service", state="active"}
OR on(instance) (up{job="node-exporter"} * 0)
同时我们需要修改下面遇到No data的情况。
-
找到 Configure no data and error handling。
-
Alert state if no data: 修改为 Normal。
为什么? 因为现在我们把“服务挂了”通过PromQL语句变成了“数值等于0”,这属于正常数据。
- 讨论2:然而我们填入上述PromQL语句后,发现查询出的条目总有一个(或多个)持续为firing状态。
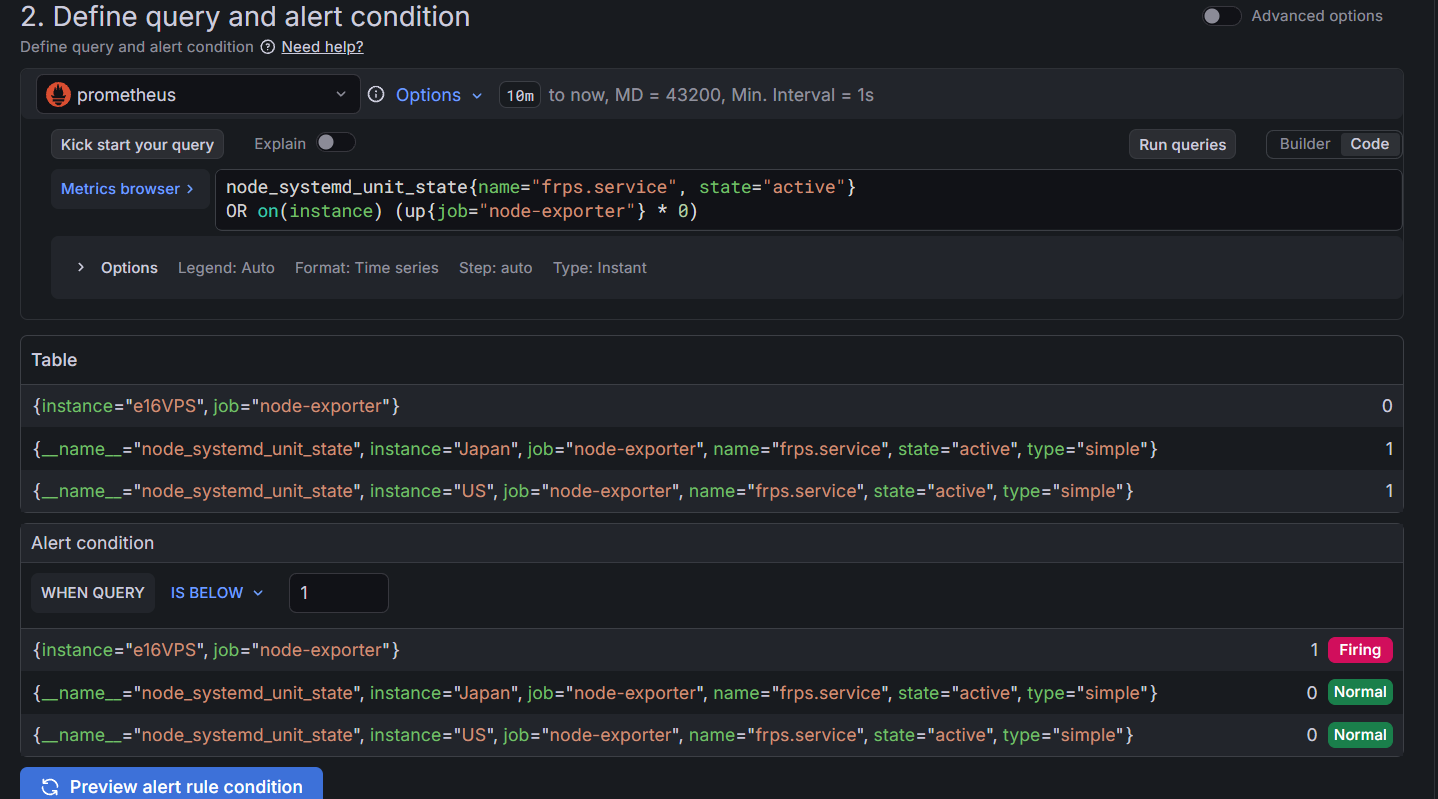
原因:e16VPS这台机器上根本没有运行frps这个服务,而语句会查询Prometheus中所有机器上的服务,因此当然这台机器会返回firing。我们需要根据机器上运行服务的实际情况,决定在哪些机器上监控这些服务。
修改PromQL语句为:
node_systemd_unit_state{name="frps.service", state="active"}
OR on(instance) (up{job="node-exporter", instance=~"Japan|US"} * 0)
现在再测试,我们已经能够得到正确的告警邮件了。
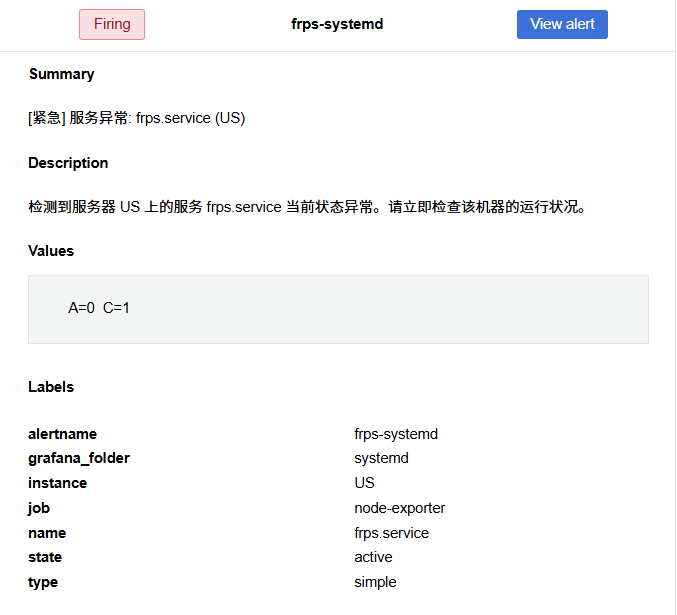
Grafana的告警规则还有很大的可扩展性,限于本人水平,本文暂未探讨。生产实践中,可以借助相关文档,实现更强大的告警通知效果。